This version is the same as we previously posted, but adds a security certificate, and lots of extra new stuff! You will need a valid certificate, this is fairly easy to setup using Let’s Encrypt, or you could do a self signed certificate.
Setting up Prerequisite
Installing whisper-ctranslate2
pip install -U whisper-ctranslate2
Install NodeJS
sudo apt install nodejs
or
sudo dnf install nodejs
Install Node Dependencies
npm install formidable npm install https npm install fs
Setting up Simple Whisper Web Interface
First we need a web directory to use.
Next lets make an uploads folder
mkdir uploads
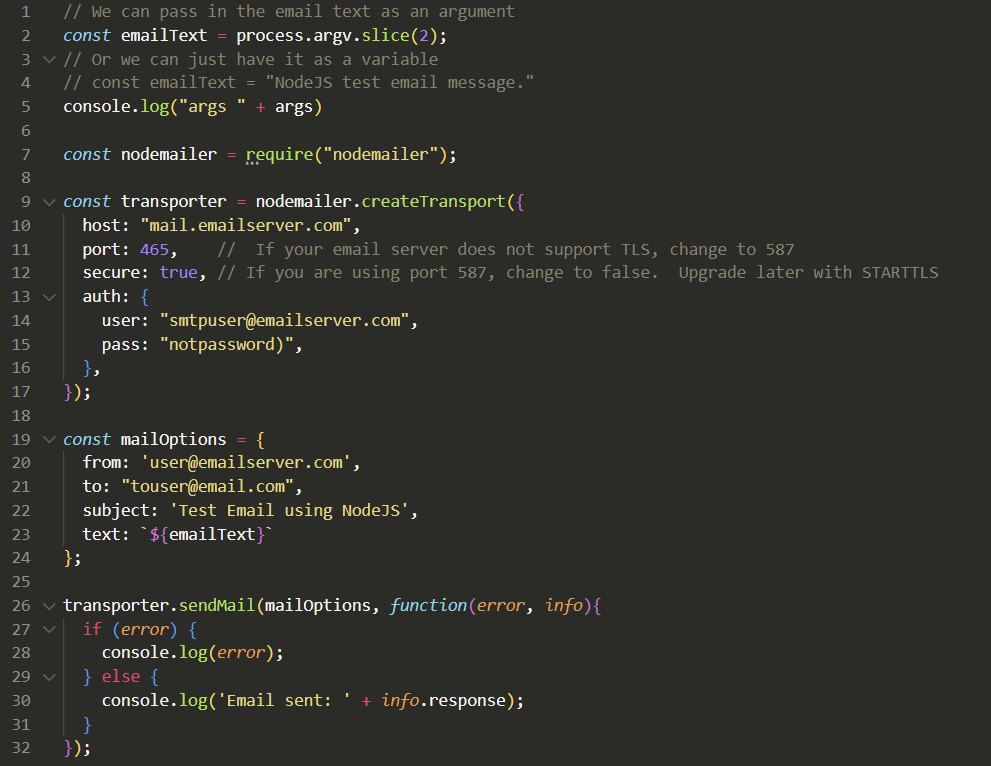
Code for main.js. Change WEBSITE.COM to your website name. Node will need access to the certificates. You can run this web app as root (If you do that, then root needs node, and prerequisites), or copy the certs to the users directory, and change the path. If you do the later, look at using a script/cronjob to copy the updated certificates to the users directory.
const http = require('http')
const https = require('https')
const formidable = require('formidable')
const fs = require('fs')
const execSync = require('child_process').execSync
let newpath = ''
let modelSize = 'medium.en'
const { exec } = require('node:child_process')
const validModels = [
'medium.en',
'tiny',
'tiny.en',
'base',
'base.en',
'small',
'small.en',
'medium',
'medium.en',
'large-v1',
'large-v2'
]
var options = {
key: fs.readFileSync('/path/to/privkey.pem'),
cert: fs.readFileSync('/path/to/fullchain.pem')
}
fs.readFile('./index.html', function (err, html) {
if (err) throw err
https
.createServer(options, function (req, res) {
if (req.url == '/fileupload') {
res.write(html)
res.write(`<div class="loading results"></div>`)
var form = new formidable.IncomingForm()
form.parse(req, function (err, fields, files) {
console.log('Fields ' + fields.modeltouse)
console.log('File ' + files.filetoupload)
var oldpath = files.filetoupload.filepath
newpath = './uploads/' + files.filetoupload.originalFilename
modelSize = validModels.includes(fields.modeltouse)
? fields.modeltouse
: 'medium.en'
console.log('modelSize::' + modelSize)
fs.rename(oldpath, newpath, function (err) {
if (err) {
console.log('No file selected!') // throw err
res.write(`<div class="results">No file selected</div>`)
} else {
console.log(newpath)
if (fields.timestamps) {
console.log("true check")
var output = execSync(
`./whisper.sh "${newpath}" ${modelSize} "true"`,
{ encoding: 'utf-8' }
)
} else {
var output = execSync(
`./whisper.sh "${newpath}" ${modelSize} false`,
{ encoding: 'utf-8' }
)
}
res.write(`<script>document.querySelector('.loading').classList.add('hidden')</script>`)
res.write(
`<div class="results"><h2>Results:</h2> <p>${output}</p></div>`
)
res.end()
}
})
})
} else {
res.writeHead(200, { 'Content-Type': 'text/html' })
res.write(html)
return res.end()
}
})
.listen(8443)
})Add the following to index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Voice Transcribing Using Whisper</title>
<link type="text/css" rel="stylesheet" href="style.css" />
</head>
<style>
body {
background-color: #b9dbe7;
align-items: center;
}
.box {
border-radius: 25px;
padding: 25px;
width: 80%;
background-color: azure;
margin: auto;
border-bottom: 25px;
margin-bottom: 25px;
font-family: 'advent_prothin', Arial, sans-serif;
}
.button {
border-radius: 25px;
margin: auto;
width: 50%;
height: 50px;
display: flex;
justify-content: center;
border-style: solid;
background-color: #e8d2ba;
}
h1 {
text-align: center;
padding: 0%;
margin: 0%;
}
@font-face {
font-family: 'advent_prothin';
src: url('Typewriter.otf');
font-weight: normal;
font-style: normal;
}
p {
font-size: larger;
font-family: 'MyWebFont', Arial, sans-serif;
}
.headings {
font-size: large;
font-weight: bold;
}
input {
font-size: medium;
}
.checkboxes {
transform: scale(1.5);
}
select {
font-size: medium;
}
.results {
white-space: pre-wrap;
border-radius: 25px;
padding: 25px;
width: 80%;
align-self: center;
background-color: azure;
margin: auto;
font-family: Typewriter;
}
.hidden {
display: none;
}
.note {
font-style: italic;
font-size: small;
font-weight: normal;
}
.loading {
border: 16px solid azure;
border-radius: 50%;
border-top: 16px solid rgb(207, 255, 255);
width: 64px;
height: 64px;
animation: spin 1s linear infinite;
}
/* Safari */
@keyframes spin {
0% {
transform: rotate(0deg);
}
100% {
transform: rotate(360deg);
}
}
</style>
<body>
<script>
</script>
<div class="box">
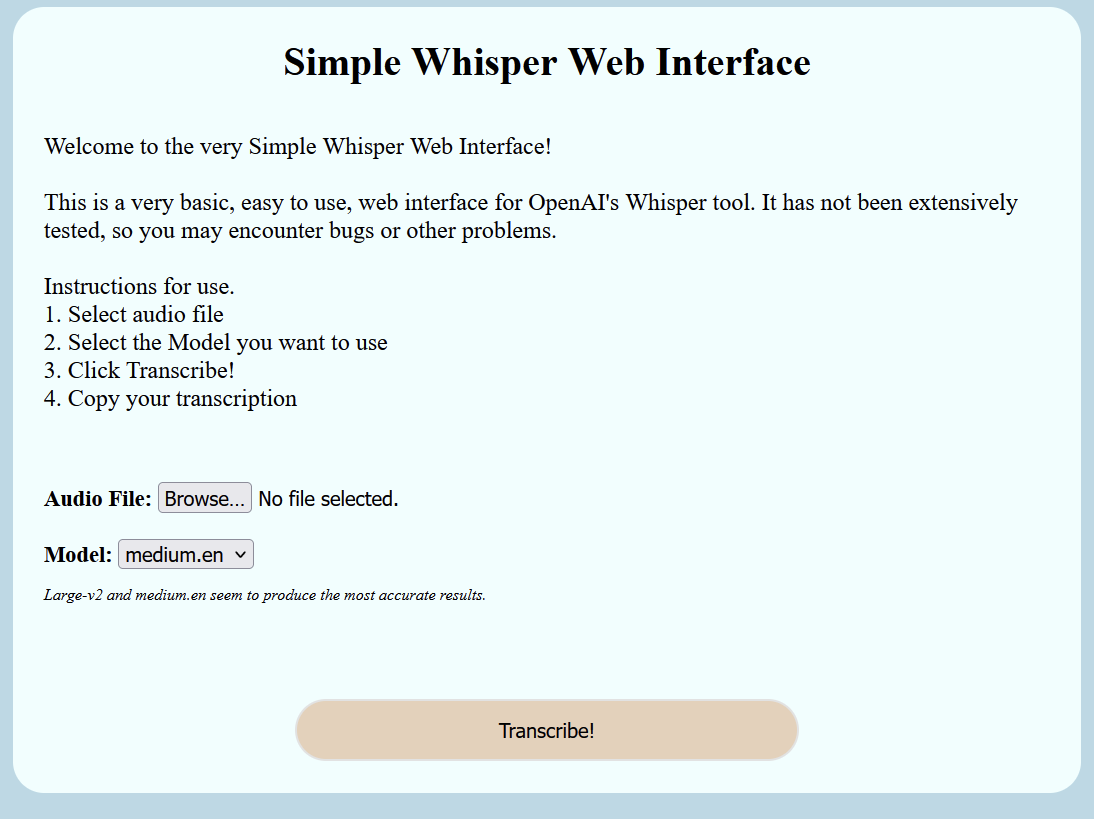
<h1>Simple Whisper Web Interface</h1>
<br />
<p>
Welcome to the very Simple Whisper Web Interface!<br /><br />
This is a very basic, easy to use, web interface for OpenAI's Whisper
tool. It has not been extensively tested, so you may encounter bugs or
other problems.
<br /><br />
Instructions for use. <br />1. Select audio file <br />2. Select the
Model you want to use <br />
3. Click Transcribe! <br />4. Copy your transcription
</p>
<br />
<br />
<div class="headings">
<form action="fileupload" method="post" enctype="multipart/form-data">
Audio File: <input type="file" name="filetoupload" /><br />
<br />
Model:
<select name="modeltouse" id="modeltouse">
<option value="medium.en">medium.en</option>
<option value="tiny">tiny</option>
<option value="tiny.en">tiny.en</option>
<option value="base">base</option>
<option value="base.en">base.en</option>
<option value="small">small</option>
<option value="small.en">small.en</option>
<option value="medium">medium</option>
<option value="medium.en">medium.en</option>
<option value="large-v1">large-v1</option>
<option value="large-v2">large-v2</option>
</select>
<p class="note">
Large-v2 and medium.en seem to produce the most accurate results.
</p>
Timestamps?
<input class="checkboxes" type="checkbox" id="timestamps" name="timestamps" />
<br />
<br />
<br />
<input class="button" type="submit" value="Transcribe!" />
</form>
</div>
</div>
</body>
</html>Run the server with
node main.js
If we want to start it in the background, run
node ./main.js &
Next steps are to setup a SystemD file so we can auto start on system boot and also make the installation quicker/easier.