
Created a little web interface to use Whisper, technically using whisper-ctranslate2 which is built on faster-whisper.
This is not currently ready to be run on the public web. It doesn’t have any sort of TLS for encrypting communications from client to server and all the files are stored on server. Only use in a trusted environment.
Setting up Prerequisite
Installing whisper-ctranslate2
pip install -U whisper-ctranslate2
Install NodeJS
sudo apt install nodejs
or
sudo dnf install nodejs
Install Node Dependencies
npm install formidable
npm install http
npm install fs
Setting up Simple Whisper Web Interface
First we need a web directory to use.
Next lets make an uploads folder
mkdir uploads
Now let’s create a main.js file. Node is going to be our webserver. Copy the following contents.
var http = require('http')
var formidable = require('formidable')
var fs = require('fs')
const execSync = require('child_process').execSync
let newpath = ''
let modelSize = 'medium.en'
const { exec } = require('node:child_process')
const validModels = [
'medium.en',
'tiny',
'tiny.en',
'base',
'base.en',
'small',
'small.en',
'medium',
'medium.en',
'large-v1',
'large-v2'
]
fs.readFile('./index.html', function (err, html) {
if (err) throw err
http
.createServer(function (req, res) {
if (req.url == '/fileupload') {
res.write(html)
var form = new formidable.IncomingForm()
form.parse(req, function (err, fields, files) {
console.log('Fields ' + fields.modeltousema)
console.log('File ' + files.filetoupload)
var oldpath = files.filetoupload.filepath
newpath = './uploads/' + files.filetoupload.originalFilename
modelSize = validModels.includes(fields.modeltouse)
? fields.modeltouse
: 'medium.en'
console.log('modelSize::' + modelSize)
fs.rename(oldpath, newpath, function (err) {
if (err) {
console.log('No file selected!') // throw err
res.write(`<div class="results">No file selected</div>`)
} else {
console.log(newpath)
const output = execSync(
`whisper-ctranslate2 ${newpath} --model ${modelSize}`,
{ encoding: 'utf-8' }
)
res.write(
`<div class="results"><h2>Results:</h2> <p>${output}</p></div>`
)
res.end()
}
})
})
} else {
res.writeHead(200, { 'Content-Type': 'text/html' })
res.write(html)
return res.end()
}
})
.listen(8080)
})
Now create an index.html file and paste the following in
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Voice Transcribing Using Whisper</title>
<link type="text/css" rel="stylesheet" href="style.css" />
</head>
<style>
body {
background-color: #b9dbe7;
align-items: center;
}
.box {
border-radius: 25px;
padding: 25px;
width: 80%;
background-color: azure;
margin: auto;
border-bottom: 25px;
margin-bottom: 25px;
}
.button {
border-radius: 25px;
margin: auto;
width: 50%;
height: 50px;
display: flex;
justify-content: center;
border-style: solid;
background-color: #e8d2ba;
}
h1 {
text-align: center;
padding: 0%;
margin: 0%;
}
p {
font-size: larger;
}
.headings {
font-size: large;
font-weight: bold;
}
input {
font-size: medium;
}
select {
font-size: medium;
}
.results {
white-space: pre-wrap;
border-radius: 25px;
padding: 25px;
width: 80%;
align-self: center;
background-color: azure;
margin: auto;
}
.note {
font-style: italic;
font-size: small;
font-weight: normal;
}
</style>
<body>
<script></script>
<div class="box">
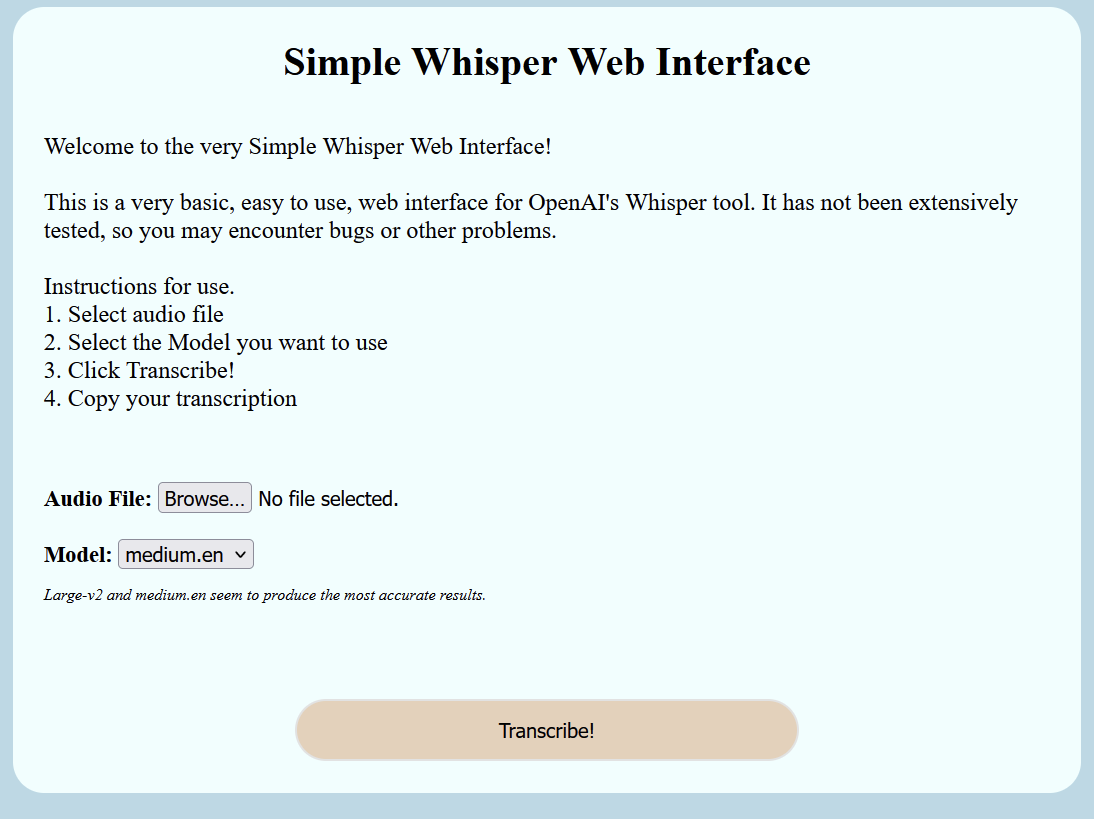
<h1>Simple Whisper Web Interface</h1>
<br />
<p>
Welcome to the very Simple Whisper Web Interface!<br /><br />
This is a very basic, easy to use, web interface for OpenAI's Whisper
tool. It has not been extensively tested, so you may encounter bugs or
other problems.
<br /><br />
Instructions for use. <br />1. Select audio file <br />2. Select the
Model you want to use <br />
3. Click Transcribe! <br />4. Copy your transcription
</p>
<br />
<br />
<div class="headings">
<form action="fileupload" method="post" enctype="multipart/form-data">
Audio File: <input type="file" name="filetoupload" /><br />
<br />
Model:
<select name="modeltouse" id="modeltouse">
<option value="medium.en">medium.en</option>
<option value="tiny">tiny</option>
<option value="tiny.en">tiny.en</option>
<option value="base">base</option>
<option value="base.en">base.en</option>
<option value="small">small</option>
<option value="small.en">small.en</option>
<option value="medium">medium</option>
<option value="medium.en">medium.en</option>
<option value="large-v1">large-v1</option>
<option value="large-v2">large-v2</option>
</select>
<p class="note">
Large-v2 and medium.en seem to produce the most accurate results.
</p>
<br />
<br />
<br />
<input class="button" type="submit" value="Transcribe!" />
</form>
</div>
</div>
</body>
</html>
Now we should be set to go.
Fire the web server up with
node ./main.js
If we want to start it in the background, run
node ./main.js &
Known Limitations or Bugs
If you hit Transcribe with no file selected, the server crashes.
We are calling whisper-ctranslate2 directly, if it is not in the path, then it won’t work.
We are currently using the medium.en model, if the model is not downloaded, then the first transcription may take awhile while it downloads. Would like to add a menu for selecting which model to use. We fixed this by adding a drop down that let’s you select a model.
Would be nice to have an option for getting rid of the timestamps.