Plotman is a great way to semi automate plot creation. It can manage all your temp and destination directories as well as spacing out plots for parallel plotting.
It will download all the correct files and set everything up. If you run into any issues, check for any errors on the terminal.
After it finishes installing, lets run “plotman version” to verify that it is working
(venv) plotter@chia1:~/chia-blockchain$ plotman version
plotman 0.3.1
(venv) plotter@chia1:~/chia-blockchain$
Configure Plotman config file
First lets generate a config that we will then edit. Use the “plotman config generate” command. It by default puts the config in ~/.config/plotman/plotman.yaml
(venv) plotter@chia1:~/chia-blockchain$ plotman config generate
Wrote default plotman.yaml to: /home/plotter/.config/plotman/plotman.yaml
(venv) plotter@chia1:~/chia-blockchain$
Use your favorite text editor to open up the config file. Nano is a easy to use terminal text editor.
nano ~/.config/plotman/plotman.yaml
Changes we need to make
Change log directory (Line 18)
Set tmp directories i.e. where temp plot files go (Line 27)
I will put a full config at the bottom of this post with the important settings in bold.
A note about the config file. The config files uses a yaml format which is picky about indentation and how things work. If you run into an error and can’t figure out what is up, the easiest thing to do may be to delete the config and regenerate it.
Change log directory
Change username to your Ubuntu username. Plotman should create the logs directory if it is not created.
log: /home/username/logs
Setup tmp directories
The tmp directories are the folders where the temporary plot files are created. Ideally each line should be a path to a physical ssd. Change the path to your SSD. If you have more, then add more lines. Note the – is needed in front.
tmp:
- /media/username/ssd
Set up destination directories
The destination directories are our drives that hold our plots. Same idea as our tmp drive setup above, but you’ll need to add the path to all your destination drives. Below is an example of how I have some set up.
You can configure the archive settings so that when a plot finishes it can copy it over the network. I am not using this feature at the moment so just add a # to the first part of the line to comment it out.
# archive:
# rsyncd_module: plots # Define this in remote rsyncd.conf.
# rsyncd_path: /plots # This is used via ssh. Should match path
# # defined in the module referenced above.
# rsyncd_bwlimit: 80000 # Bandwidth limit in KB/s
# rsyncd_host: myfarmer
# rsyncd_user: chia
Scheduling!
Now this is the confusing part, but don’t worry! I’ll do my best to explain what is going on to the best of my knowledge. The defaults do work, but this is where the tuning is going to create the most Plots per day. Below I put in bold the options we’ll want to look at and then we’ll go through those options and explain what they mean.
scheduling:
# Run a job on a particular temp dir only if the number of existing jobs
# before [tmpdir_stagger_phase_major : tmpdir_stagger_phase_minor]
# is less than tmpdir_stagger_phase_limit.
# Phase major corresponds to the plot phase, phase minor corresponds to
# the table or table pair in sequence, phase limit corresponds to
# the number of plots allowed before [phase major : phase minor].
# e.g, with default settings, a new plot will start only when your plot
# reaches phase [2 : 1] on your temp drive. This setting takes precidence
# over global_stagger_m
tmpdir_stagger_phase_major: 2
tmpdir_stagger_phase_minor: 1
# Optional: default is 1
tmpdir_stagger_phase_limit: 1
# Don't run more than this many jobs at a time on a single temp dir.
tmpdir_max_jobs: 3
# Don't run more than this many jobs at a time in total.
global_max_jobs: 12
# Don't run any jobs (across all temp dirs) more often than this, in minutes.
global_stagger_m: 30
# How often the daemon wakes to consider starting a new plot job, in seconds.
polling_time_s: 20
Are what plotman uses to figure out when to start the next plot. I’ll see about posting some info soon about the different phases a plot goes through, but there are phases 1:1 – 4:something, so when the first plot phase hits 2:1, it will launch another parallel plot.
This is helpful because the different phases use different portions of a system, first phase is multi threaded and uses more CPU, where as other phases can use more storage. So by waiting for a plot to hit a certain phase before launching another plot can increase the efficiency of the computers components.
The next option is
tmpdir_stagger_phase_limit: 1
This is how many plotting jobs you can have running before the major:minor phases (Above options). By default it is 1. Meaning that plotman launches a job, once that job hits phase 2:1, it launches another job, once that new job hits 2:1, it launches a 3rd job, so you have 3 jobs running. But only one of those jobs is pre 2:1 phase.
tmpdir_max_jobs
The following option
tmpdir_max_jobs: 3
is the limit on how many jobs can run on a single tmp directory. If you are using a 2TB NVME SSD for plotting, you will probably want to increase this to allow up to 6-8 (maybe more?) jobs to run at the same time. Note that a 1TB SSD is is going to be limited to about 4 plots, maybe 5 if you were super precise with your timing. I have been running 4 though.
global_max_jobs: 12
This option is the total jobs limit. This number will probably be dependent on CPU, RAM, and SSD(s). This guy has some helpful information for calculating that out. I will say I don’t think you want to exceed your CPU thread count. So if you have a Ryzen 5600X, I would not go more then 12 jobs just from a CPU perspective.
This option is how many minutes to wait before starting a new job. 30 minutes seems like a good number so you can probably leave it. The previous options do override this though. So if your above setting for the phase_limit is 1, and it takes 1 hour for a plot to go from 1:1 to 2:1, then it will be starting a new job every hour. Or whenever the job gets past 2:1.
Add Farmer and Pool keys
Almost there! The following options are optional, but if you are running a harvester and generating plots for a different node, you’ll probably want to update the farmer_pk and pool_pk
Save the file. You should now have a good plotman config file to work from.
Running Plotman
Tip: Plotman launches the jobs in the background, so if you need to make a config change, kill plotman with ctrl+c and edit the config. When you relaunch plotman, it will scan for the existing jobs and pick up from there.
Plotman -h offers a bunch of helpful options. One of which is plotman status which will list active jobs. Side note that it shows the phase a job is in.
(venv) plotter@chia1:~/chia-blockchain$ plotman status
plot id k tmp dst wall phase tmp pid stat mem user sys io
1569c6a8 32 /mnt/chia3/tmp /mnt/chia5 0:07 1:2 39G 26063 SLP 4.0G 0:07 0:01 0s
# Default/example plotman.yaml configuration file
# Options for display and rendering
user_interface:
# Call out to the `stty` program to determine terminal size, instead of
# relying on what is reported by the curses library. In some cases,
# the curses library fails to update on SIGWINCH signals. If the
# `plotman interactive` curses interface does not properly adjust when
# you resize the terminal window, you can try setting this to True.
use_stty_size: True
# Where to plot and log.
directories:
# One directory in which to store all plot job logs (the STDOUT/
# STDERR of all plot jobs). In order to monitor progress, plotman
# reads these logs on a regular basis, so using a fast drive is
# recommended.
log: /home/plotter/logs
# One or more directories to use as tmp dirs for plotting. The
# scheduler will use all of them and distribute jobs among them.
# It assumes that IO is independent for each one (i.e., that each
# one is on a different physical device).
#
# If multiple directories share a common prefix, reports will
# abbreviate and show just the uniquely identifying suffix.
tmp:
- /mnt/chia0/tmp
# Optional: Allows overriding some characteristics of certain tmp
# directories. This contains a map of tmp directory names to
# attributes. If a tmp directory and attribute is not listed here,
# it uses the default attribute setting from the main configuration.
#
# Currently support override parameters:
# - tmpdir_max_jobs
tmp_overrides:
# In this example, /mnt/tmp/00 is larger than the other tmp
# dirs and it can hold more plots than the default.
"/mnt/tmp/00":
tmpdir_max_jobs: 5
# Optional: tmp2 directory. If specified, will be passed to
# chia plots create as -2. Only one tmp2 directory is supported.
# tmp2: /mnt/tmp/a
# One or more directories; the scheduler will use all of them.
# These again are presumed to be on independent physical devices,
# so writes (plot jobs) and reads (archivals) can be scheduled
# to minimize IO contention.
dst:
- /mnt/chia0
- /mnt/chia1
- /mnt/chia2
- /mnt/chia3
- /mnt/chia4
- /mnt/chia5
# Archival configuration. Optional; if you do not wish to run the
# archiving operation, comment this section out.
#
# Currently archival depends on an rsync daemon running on the remote
# host.
# The archival also uses ssh to connect to the remote host and check
# for available directories. Set up ssh keys on the remote host to
# allow public key login from rsyncd_user.
# Complete example: https://github.com/ericaltendorf/plotman/wiki/Archiving
archive:
rsyncd_module: plots # Define this in remote rsyncd.conf.
rsyncd_path: /plots # This is used via ssh. Should match path
# defined in the module referenced above.
rsyncd_bwlimit: 80000 # Bandwidth limit in KB/s
rsyncd_host: myfarmer
rsyncd_user: chia
# Optional index. If omitted or set to 0, plotman will archive
# to the first archive dir with free space. If specified,
# plotman will skip forward up to 'index' drives (if they exist).
# This can be useful to reduce io contention on a drive on the
# archive host if you have multiple plotters (simultaneous io
# can still happen at the time a drive fills up.) E.g., if you
# have four plotters, you could set this to 0, 1, 2, and 3, on
# the 4 machines, or 0, 1, 0, 1.
# index: 0
# Plotting scheduling parameters
scheduling:
# Run a job on a particular temp dir only if the number of existing jobs
# before [tmpdir_stagger_phase_major : tmpdir_stagger_phase_minor]
# is less than tmpdir_stagger_phase_limit.
# Phase major corresponds to the plot phase, phase minor corresponds to
# the table or table pair in sequence, phase limit corresponds to
# the number of plots allowed before [phase major : phase minor].
# e.g, with default settings, a new plot will start only when your plot
# reaches phase [2 : 1] on your temp drive. This setting takes precidence
# over global_stagger_m
tmpdir_stagger_phase_major: 2
tmpdir_stagger_phase_minor: 1
# Optional: default is 1
tmpdir_stagger_phase_limit: 1
# Don't run more than this many jobs at a time on a single temp dir.
tmpdir_max_jobs: 3
# Don't run more than this many jobs at a time in total.
global_max_jobs: 6
# Don't run any jobs (across all temp dirs) more often than this, in minutes.
global_stagger_m: 30
# How often the daemon wakes to consider starting a new plot job, in seconds.
polling_time_s: 20
# Plotting parameters. These are pass-through parameters to chia plots create.
# See documentation at
# https://github.com/Chia-Network/chia-blockchain/wiki/CLI-Commands-Reference#create
plotting:
k: 32
e: False # Use -e plotting option
n_threads: 2 # Threads per job
n_buckets: 128 # Number of buckets to split data into
job_buffer: 3389 # Per job memory
# If specified, pass through to the -f and -p options. See CLI reference.
farmer_pk: farmerkey
pool_pk: poolkey
This is a basic script for starting the Chia Harvester on Ubuntu. You can download the script here or use the following commands to download with wget.
#!/bin/bash
# Script for starting the Chia Harvester
cd ~/chia-blockchain/
. ./activate
chia start harvester
sleep 5
if ( echo $(ps aux | grep -v grep | grep chia_harvester) | grep chia_harvester); then
echo "Harvester started"
else
echo "Looks like the harvester is not running, try manually checking and/or running the commands to figure out what is wrong."
fi
Fortunately, installing the NVIDIA drivers on Ubuntu is easy. Fire up a terminal and paste in the following command. There is a little bit of human interaction, but it is fairly straight forward.
Apparently on some versions of Java checking the Java version will give you the following error.
root@local:~# java -v
Unrecognized option: -v
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
root@local:~#
The issue being the -v or –version options are not recognized. On newer versions of Java it is recognized.
The proper way to do it is -version with only one dash
root@local:~# java -version openjdk version "1.8.0_252" OpenJDK Runtime Environment (build 1.8.0_252-8u252-b09-1ubuntu1-b09) OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode) root@local:~#
rsnapshot is a utility that uses rsync to backup files locally or it can backup files from a remote server.
While trying to figure out a good solution for backing up an Ubuntu Server I decided to try rsnapshot, however since it can either create a local backup or pull a remote backup it needs to be configured to do that on the backup server side. It does not “push” a backup to a backup server.
Some helpful snippits from the man file.
rsnapshot will typically be invoked as root by a cron job, or series of cron jobs. It is possible, however, to run as any arbitrary user with an alternate configuration file.
...
USAGE
rsnapshot can be used by any user, but for system-wide backups you will probably want to run it as root.
...
NOTES
Make sure your /etc/rsnapshot.conf file has all elements separated by tabs. See
/usr/share/doc/rsnapshot/examples/rsnapshot.conf.default.gz for a working example file.
Make sure you put a trailing slash on the end of all directory references. If you don't, you may have extra directories created in your snapshots. For more information on how the trailing slash is handled, see the rsync(1) manpage.
Overview
Scenario
Host A runs xyz application and host B is the backup server. We create a backup user on host A, host B then uses that user to ssh and rsync backups to itself.
Create backup user
Configure rysnc to be used without a password
Setup SSH Key, aka Passwordless authentication (On backup server)
Setup rsnapshot config (On backup server)
Configure rsnapshot in crontab (On backup server)
Final Testing
Create backup user
The following commands are fairly straight forward. Change backupuser to whatever you want to call your backup user.
We need to setup the backup user to be able to use “sudo rsync” without having to input the user password. If we don’t use sudo we can’t access system files for backups. And if we have to manually input the password every time rsync runs, then the backups would not be automatic. The following link was helpful.
All we need to do is create a file in /etc/sudoers.d/username and then tell it we don’t need to enter a password when “sudo rsync” is run.
sudo tee /etc/sudoers.d/backupuser <<<'backupuser ALL = (root) NOPASSWD: /usr/bin/rsync'
Setup SSH Key, aka Passwordless authentication (On backup server)
Log into the backup server
Create SSH keys. Note that since rsnapshot wants to run as root, we create the key and copy it as the root user.
sudo ssh-keygen
Accept all the defaults so we can login from the backup server without having to enter in a password.
Copy ssh key to the server we are wanting to back up
sudo ssh-copy-id backupuser@ip
enter in the password and the the key should get copied it over. Once complete, verify that you can login without having to enter in a password.
Setup rsnapshot config (On backup server)
Open up the rsnapshot config file and modify where appropriate. /etc/rsnapshot.conf
Change the path to where the snapshots are stored. By default it stores them under /.snapshots. I moved it under a local user as I am not needing to use rsnapshot to backup the local backup server files.
Setup remote server to get a backup from. Replace ipaddress and directories as needed. hostname is the sever name. You can change to whatever you want.
### BACKUP POINTS / SCRIPTS ###
# LOCALHOST
# Comment or delete entries unless you want to backup those as well
# EXAMPLE.COM
backup backupuser@ipaddress:/home/ hostname/ +rsync_long_args=--rsync-path="sudo rsync"
If you would like to back up multiple locations you can create multiple entries with different remote paths. Example locations to add
These steps should work for multiple versions of Ubuntu Server.
Thankfully enabling automatic updates in Ubuntu is super easy.
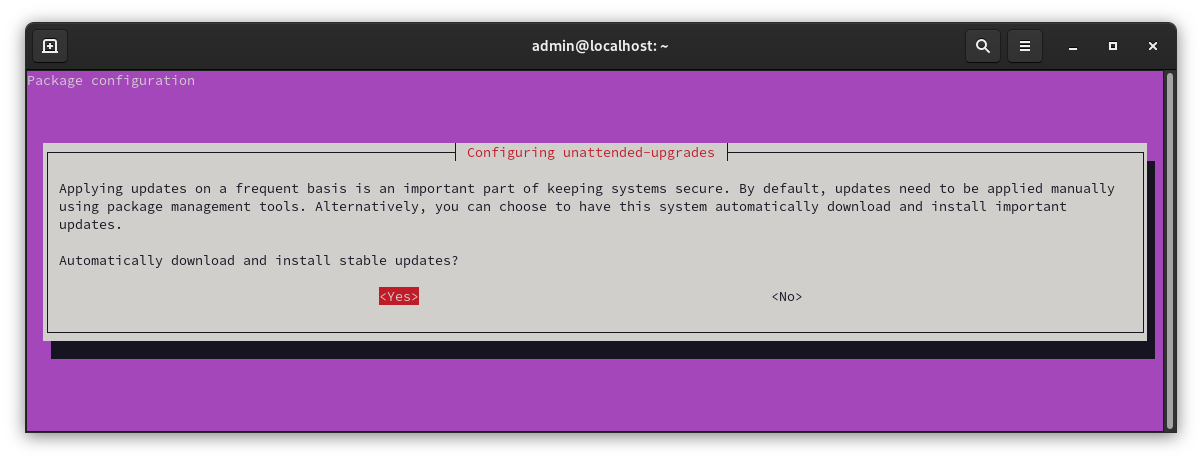
First make sure that the “unattended-upgrades” package is installed
sudo apt install unattended-upgrades
It was already installed on my Ubuntu 20.04 server instance. Next run dpkg to reconfigure and enable updates
sudo dpkg-reconfigure unattended-upgrades
You should get the following prompt.
Configuring automatic updates
Hit “Yes” to enable.
Your system should now automatically install updates. however, if it needs to reboot it may not. You can configure the reboot options in
sudo vi /etc/apt/apt.conf.d/50unattended-upgrades
Scroll down to the Reboot lines and uncomment
// Automatically reboot *WITHOUT CONFIRMATION* if
// the file /var/run/reboot-required is found after the upgrade
Unattended-Upgrade::Automatic-Reboot "true"; // <- Uncomment line
// If automatic reboot is enabled and needed, reboot at the specific
// time instead of immediately
// Default: "now"
Unattended-Upgrade::Automatic-Reboot-Time "02:00"; // <- Uncomment line
Save the file. Your system should now automatically install stable updates.
Disable automatic update
You can disable the automatic updates by running the dpkg command again.
sudo dpkg-reconfigure unattended-upgrades
and selecting “No”
Automatic updates should now be off.
More information can be found at the following link.
Unfortunately once a version of Ubuntu becomes unsupported you can run into problems upgrading to the latest version. As is the case when you try to upgrade disco to focal. Ubunut 19.04 to 20.04.
A work around is to update the apt sources and then run an update
Update Apt Sources with.
sudo sed -i 's/disco/focal/g' /etc/apt/sources.list